Cross-Entropy Demystified
What is it? Is there any relation to the entropy concept?

What is it? Is there any relation to the entropy concept? Why is it used for classification loss? What about the binary cross-entropy?
Some of us might have used cross-entropy for calculating classification losses and wondered why we use the natural logarithm. Some might have seen the binary cross-entropy and wondered whether it fundamentally differs from the cross-entropy. If so, reading this article should help to demystify those questions.
The word “cross-entropy” has “cross” and “entropy” in it, and it helps to understand the “entropy” part to understand the “cross” part.
So, let’s review the entropy formula.
1 Review of Entropy Formula
The previous article should help you understand the entropy concept in case you are not already familiar with it.
Claude Shannon defined the entropy to calculate the minimum encoding size as he was looking for a way to efficiently send messages without losing any information.
As we will see below, there are various ways of expressing entropy.
The entropy of a probability distribution is as follows:
We assume that we know the probability
For continuous variables, we can be write it using the integral form:
Here,
In both discrete and continuous variable cases, we are calculating the expectation (average) of the negative log probability, which is the theoretical minimum encoding size of the information from the event
So, the above formula can be re-written in the expectation form as follows:
We can write the entropy using
People use all these notations interchangeably, and we see them used in different places when we read articles and papers that use entropy concepts.
In short, the entropy tells us the theoretical minimum average encoding size for events that follow a particular probability distribution.
As long as we know the probability distribution of anything, we can calculate its entropy.
We cannot calculate the entropy if we do not know the probability distribution. So, we would need to estimate the probability distribution.
However, what does it mean to estimate the entropy?
Also, how accurate would that be?
Answering these questions gets us to the cross-entropy concept.
2 Estimating Entropy
Let’s assume we are reporting Tokyo’s weather to New York and want to encode the message into the smallest possible size. We do not know the distribution of the weather before it happens. For the sake of discussion, let’s assume we can find it out after observing the weather in Tokyo for some time.
We do not initially know the probability distribution of Tokyo’s weather, so we estimate it as
Using the estimated probability distribution
If
However, there are two kinds of uncertainty involved in the estimation formula.
As indicated by
Moreover, we estimate the minimum encoding size as
The estimated probability distribution
Alternatively, it can be close to the real entropy by coincidence because
So, comparing the estimated entropy with the real entropy may not mean anything.
Like Claude Shannon, our main concern is making the encoding size as small as possible. So, we want to compare our encoding size with the theoretical minimum encoding size based on entropy.
Suppose we have the real distribution
It is called the cross-entropy between
We are comparing apple to apple as we use the same true distribution for both expectation calculations. We are comparing the theoretical minimum and actual encoding used in weather reporting.
In short, we are cross-checking the encoding size, which is what “cross” means in cross-entropy.
3 Cross-entropy ≥ Entropy
Commonly, we express the cross-entropy H as follows:
This point is subtle but essential. For the expectation, we should use the true probability
Since the entropy is the theoretical minimum average size, the cross-entropy is higher than or equal to the entropy but not less than that.
In other words, if our estimate is perfect,
I hope the connection between hentropy and cross-entropy should be clear. Let’s talk about why we use cross-entropy for the classification loss function.
4 Cross-Entropy as a Loss Function
Let’s say we have a dataset of animal images with five different animals. Each image has only one animal in it.

Each image is labeled with the corresponding animal using the one-hot encoding.
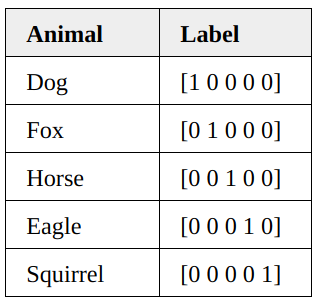
We can treat one-hot encoding as a probability distribution for each image. Let’s see a few examples.
The probability distribution of the first image being a dog is 1.0 (=100%).
For the second image, the label tells us that it is a fox with 100% certainty.
and so on.
As such, the entropy of each image is zero.
In other words, one-hot encoded labels tell us what animal each image has with 100% certainty. It is not like the first image can be a dog for 90% and a cat for 10%. It is always a dog, and there will be no surprise.
Let’s say we have a machine-learning model that classifies those images. When we have not adequately trained the model, it may classify the first image (dog) as follows:
The model says the first image is 40% for a dog, 30% for a fox, 5% for a horse, 5% for an eagle, and 20% for a squirrel. This estimation is not very precise or confident about what animal the first image has.
In contrast, the below label gives us the exact distribution of the first image’s animal class. It tells us it is a dog with 100% certainty.
So, how well was the model’s prediction? We can calculate the cross-entropy as follows:
The value is higher than the zero entropy of the label, but we do not have an intuitive sense of what this value means. So, let’s see another cross-entropy value for comparison.
After the model is well-trained, it may produce the following prediction for the first image.
As seen below, the cross-entropy is much lower than before.
The cross-entropy compares the model’s prediction with the label, which is the true probability distribution. The cross-entropy goes down as the prediction gets more and more accurate. It becomes zero if the prediction is perfect. As such, cross-entropy can be a loss function to train a classification model.
5 Notes on Nats vs. Bits
In machine learning, we use base e instead of base 2 for multiple reasons (one of them being the ease of calculating the derivative).
The change of the logarithm base does not cause any problem since it changes the magnitude only.
For example, using the cross-entropy as a classification cost function still makes sense as we only care about reducing it by training the model better and better.
As a side note, the information unit with the base e logarithm is nats, whereas the information unit with the base 2 logarithm is called bits. 1 nat information comes from an event with 1/e probability.
The base e logarithms are less intuitive than the base 2 logarithms. The amount of information in 1 bit comes from an event with 1/2 probability. If we can encode a piece of information in 1 bit, one such message can reduce 50% uncertainty. The same analogy is not easy to make with base e, which is why the base 2 logarithm is often used to explain the information entropy concept. However, the machine learning application uses the base e logarithm for implementation convenience.
6 Binary Cross-Entropy
We can use binary cross-entropy for binary classification where we have yes/no answers. For example, there are only dogs or cats in the images.
For the binary classifications, the cross-entropy formula contains only two probabilities:
Using the following relationship:
, we can write the cross-entropy as follows:
We can further simplify it by changing the symbols slightly:
Then, the binary cross-entropy formula becomes:
, which may look more familiar to some of us.
In short, the binary cross-entropy is a cross-entropy with two classes. Other than that, they are the same concept.
Now that we know the concepts well, the entropy of the cross-entropy concept should be zero for all of us.
7 References
- Information Entropy
Wikipedia - Cross-entropy
Wikipedia - A Short Introduction to Entropy, Cross-Entropy, and KL-Divergence
Aurélien Géron