CycleGAN
Turn a Horse into a Zebra and vice versa with the Magic of Self-Supervised Learning

This article explains how CycleGAN (aka Cycle-consistent GAN) works, which is well-known for the demo that translates horse into zebra and vice versa.
The previous article discussed pix2pix, which does similar image translations. The same people that worked on pix2pix developed CycleGAN to overcome problems in pix2pix. So, let’s first see what kind of problems exist in pix2pix, which is valuable knowledge for us to understand CycleGAN better.
1 The Inconvenient Truth about Pix2Pix
1.1 It Needs Pairs of Images for Training
In pix2pix, it is possible to convert the contents of an image into a different style, called image-to-image translation. For example, you can generate a photo-like image from a sketch image. However, since pix2pix uses supervised learning, we must have a lot of pairs of images for training.

In the above example paired image sets,
1.2 One-way Image Generation Training
In pix2pix, we train one generator network in one-way image generation. For example, suppose a generator translates from a black-and-white sketch into a colored image. If we want to perform a reverse image-to-image translation (from a colored image to a black-and-white image), we must train another generator separately.

It means we need to conduct training twice using the same dataset. Instead, it’d be more efficient if we trained two generator networks for both directions simultaneously in one training loop. It should take half the time to train two generator networks independently. It is possible in pix2pix to train two generator networks in one training loop using two discriminator networks. CycleGAN does precisely that and takes it further to eliminate the need for paired images by using unsupervised (self-supervised) learning to train two generator networks for both directions simultaneously.
2 How CycleGAN works
2.1 Unpaired Image Sets
CycleGAN uses two sets of images, but there is no need for one-to-one pairs. In the example below,

In the above, each dataset has a unique texture and style.
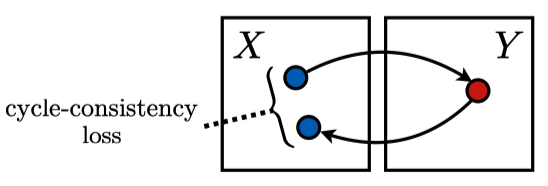
The answer is that it has cycle-consistency loss and adversarial loss. Let’s review the adversarial loss and look at the cycle-consistency loss afterward.
2.2 Adversarial Loss
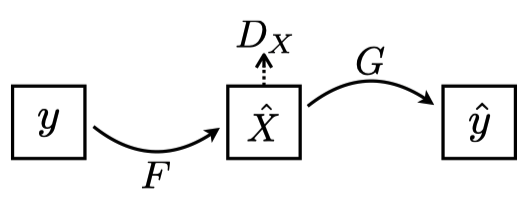
Let
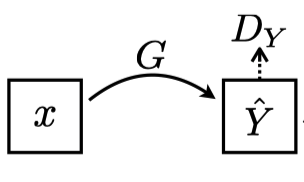
Note: In the above diagram, the paper uses $Y# with a hat since generated images
Here the discriminator network
Since there is no label image corresponding to
The generator network
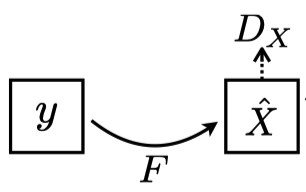
Note: In the above diagram, the paper uses
The discriminator network
So far, we have two generators for both directions:
We need the most crucial device in CycleGAN to solve all these pending issues, which we discuss next.
2.3 Cycle-Consistency Loss
Let’s think about how to train the generator networks
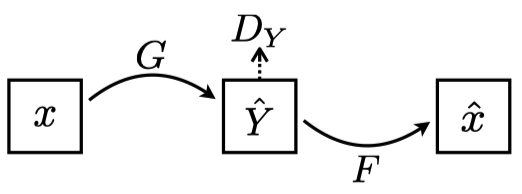
The cycle-consistency loss is the mean L1 loss between
For the loss to be lower,
Note: In pix2pix, we used L1 loss between
We also apply the cycle consistency from
As shown in the above image, we make sure
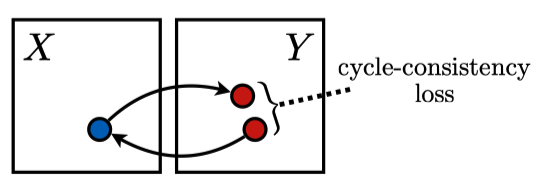
The cycle-consistency loss is the mean L1 loss between
CycleGAN uses the total cycle-consistency loss (or simply cycle-consistency loss), the sum of the mean L1 losses for both directions. It ensures the generators keep the contents of input images into generated images without paired (labeled) image sets. As a bonus, we can train two generators simultaneously, like killing two birds with one stone.
Below is an example from the paper, and you can see a comparison of the horse image converted to a zebra and further converted back to a horse image.

The complete objective of CylceGAN training is to minimize the following loss, containing two adversarial losses and the cycle-consistency loss, which is the sum of two mean L1 losses.
𝜆 is a hyperparameter to balance between the adversarial losses and the cycle-consistency loss. Thanks to this loss, we can use unsupervised (or self-supervised) training to train two generator networks, that is, without labeled datasets (paired image datasets).

However, there is one more trick we need to introduce to cater to an edge case.
2.4 Identity Mapping Loss
Training CycleGAN between Monet’s paintings and Flickr’s photos resulted in image transformations that looked like a day-night switch. Compare the Input and CycleGAN columns in the figure below. The color is changing as if the time zone has changed.

Even if it appears that the day and night have switched, the discriminator network still thinks the image is authentic from the look and feel. Also, the cycle consistency loss (the L1 loss) only looks at the average error and does not recognize the individual colors. As such, the paper introduced identity mapping loss to improve the situation. You can see the effect by looking at the CycleGAN+Lidentity (the rightmost) column in the above figure.
This loss function is for learning not to change the image’s style (including colors) when the generator network takes an image from the target dataset. For example,
The trick works well enough, but the paper does not justify why it does. In the CycleGAN Github issue, there is a question about it:
Hi
Thank you for posting this wonderful code but I am wondering what is the intuition behind the two losses `loss_idt_A` and `loss_idt_B` mentioned in the `cycle_gan_model.py` file? By reading through the implementation it seems like the loss is supposed to discourage the generator to translate the image in case it is already in the correct domain. Like if the image is in `domain B` then `G_A` should act as identity and not try to translate it?
Though I understand the intuition behind this loss, I have several questions pertaining to it
[1] why exactly is the loss relevant? since it is a controlled training setup where we know the images are coming from which domain, why would we send `domain B` images through `G_A`?
[2] Is this loss relevant to the testing time when the domain of the image is unknown?
[3] Is the loss mentioned anywhere in the paper?
[4] Is the loss helpful in generating the images? has any benchmarking been done for this?
Thanks again for the code! Hoping to get the doubts cleared soon!https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/322
The paper’s author mentioned his reasoning by answering the question about why identity mapping loss works.
This is a great question. For your questions:
1. You are right. This loss can regularize the generator to be near an identity mapping when real samples of the target domain are provided. If something already looks like from the target domain, you should not map it into a different image.
2. Yes. The model will be more conservative for unknown content.
3. It was described in Sec 5.2 "Photo generation from paintings (Figure 12) " in the CycleGAN paper. The idea was first proposed by Taigman et al's paper. See Eqn (6) in their paper.
4. It depends on your goal and it is quite subjecive. We don't have a benchmark yet. But Fig 9 in the paper illustrate the difference. In general, it can help bette preserve the content if that is your priority.
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/322
In summary, the identity mapping loss prevents the generator network from making significant changes when the input image contains unknown elements. Therefore, minimizing the loss of self-identity ensures CycleGAN does not change its style from night to day. I feel this area requires further research (if not already done).
In any case, CycleGAN works well. Let’s look at example outputs.
3 Example Outputs
There are a lot of examples at the end of the paper. I highly recommend having a look at them if you are curious.

It’s interesting to see Ukiyo-e (浮世絵) style along with Monet, Van Gogh, and Cezanne.
There are some failed cases, too.

More examples are there on their website.
4 References
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros
https://junyanz.github.io/CycleGAN/