DistilBERT — distilled version of BERT
A Tiny BERT with Great Performance – 97% of the Original

In 2019, the team at Hugging Face released a model based on BERT that was 40% smaller and 60% faster while retaining 97% of the language understanding capability. They called it DistilBERT.
1 How Small Is DistilBERT?
So, exactly how small is DistilBERT? The below chart compares the size of DistilBERT with large-scale pre-trained language models from 2018 to 2019.
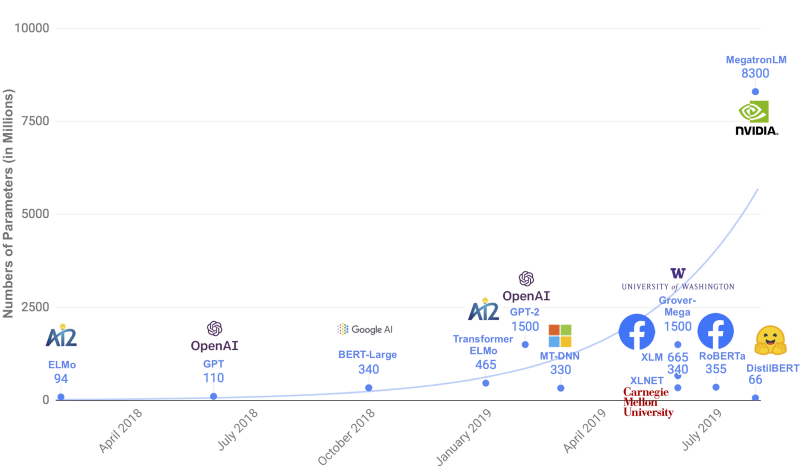
Although not shown in the chart, the BERT-Base is one-third of the BERT-Large containing 110M parameters, whereas DistilBERT is even 40% smaller than that. Yes, it’s a lot smaller, but why should we care?
There are two reasons: the first is the environmental cost. Exponentially scaling the number of model parameters increases computational requirements proportionally, consuming lots of electric energy. The second is large models won’t work well on small devices like smartphones. Ideally, we want a smaller model that is equivalently performant as larger ones.
The question is: is it possible to teach a smaller model what larger models can achieve?
2 The Tripple Loss
The Hugging Face team answered YES, as they were able to teach the small DistilBERT to learn from larger BERT models, utilizing knowledge distillation with the triple loss:
- Cross-Entropy Loss
- Distillation Loss
- Cosine Embedding Loss
To introduce these losses, let’s start discussing knowledge distillation. In 2006, Caruana and his collaborators compiled the knowledge in an ensemble of models into a single model. In 2015, Geoffrey Hinton’s team applied the same idea to deep learning, transferring the knowledge in a large model into a smaller model. They called it knowledge distillation, where we call a smaller model “student” and a larger model “teacher”.
A student has two objectives. One is the supervised training loss to minimize the cross-entropy between the student’s predicted distribution and the one-hot empirical distribution of training labels. It’s the standard classification loss term. The other is the distillation loss to minimize the KL divergence between the student’s predicted distribution and the teacher’s, which induces the student to produce a similar probability distribution. More intuitively, the student learns to think as the teacher does.
The teacher may assign small probabilities to incorrect answers, and these probabilities manifest in how the teacher generalizes. Hinton says in the paper:
An image of a BMW, for example, may only have a very small chance of being mistaken for a garbage truck, but that mistake is still many times more probable than mistaking it for a carrot. Distiling the Knowledge in a Neural Network
Therefore, the student can benefit by learning from all the probabilities the teacher produces. However, minimizing the KL divergence between the student and the teacher has one problem. A well-trained teacher signals so weakly to incorrect answers that the student may not learn much. In other words, a well-trained teacher produces a very sharp distribution with a significant probability of the correct answer, and the rest is near zero, almost the same as a one-hot encoded correct label, making the distillation loss useless.
Hinton used the softmax-temperature T as shown below:
When
In DistilBERT, they applied the same temperature
3 Performance Results
BERT had 12 encoder blocks that alternate multi-head self-attention and feed-forward layers. DistilBERT reduced the number of layers by half. They kept using 768-dimensional embedding vectors because reducing the vector dimension didn’t significantly impact computation efficiency. Besides, keeping the same dimensionality has multiple benefits.
First, while reducing the number of layers by half, they could still reuse the weights to initialize DistilBERT, which had a significant performance benefit. Next, using the same dimensionality allowed them to use cosine-distance loss between DistilBERT and BERT, another kind of distillation loss that tends to align the directions of the student and teacher’s hidden state vectors.
As for training, they followed RoBERTa. DistilBERT trained a lot faster. According to the paper, DistilBERT required 8 (16GB) V100 GPUs for approximately 90 hours, whereas the RoBERTa model required one day of training on 1024 32GB V100.
DistilBERT retains 97% of BERT performance on the GLUE benchmark:

They tested DistilBERT on iPhone 7 Plus and found it runs 71% faster than BERT.
Finally, they performed an ablation study to see the effect of those three losses. The supervised training loss is the masked language modeling loss:
They trained models with various combinations of the losses:

From the top, the combinations are:
- Triple loss (
As a result, removing the Masked Language Modeling loss has little impact. In other words, the student learns more from the teacher than from the training data.
4 References
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor SANH, Lysandre DEBUT, Julien CHAUMOND, Thomas WOLF - Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, Jeff Dean - Model compression
C. Buciluǎ, R. Caruana, A. Niculescu-Mizil