LLaMA (2023)
Open and Efficient Foundation Language Models

On February 24, 2023, Meta AI Research unveiled their cutting-edge language model, LLaMA (Large Language Model Meta AI). On March 3rd, user “llamanon” leaked the model (with its weights) on 4chan, allowing anyone to download it, which led to various fine-tuned versions being developed.
The following is a list of examples, to name a few:
- Alpaca by Stanford
- Vicuna by UC Berkeley, CMU, Stanford, UC San Diego, and MBZUAI
- Koala by BAIR (Berkeley AI Research)
These models are also available through the Hugging Face Hub.
LLaMA consists of a family of language models with parameters ranging from 7B to 65B, trained on publicly available datasets to achieve the best possible performance at various inference budgets. As such, the paper title says “LLaMA: Open and Efficient Foundation Language Models”.
LLaMA-13B outperforms GPT-3 (175B) on most benchmarks while being 10x smaller. Furthermore, it can run on a single GPU. LLaMA-65B is competitive with the best models, such as Chinchilla-70B and PaLM-540B.
This article will explain the modifications to the Transformer architecture and performance comparison with other LLMs.
1 LLaMA Architecture
Like GPT-3, LLaMA uses the Transformer’s decoder-only architecture for text generation. It also benefits from enhancements made in other models, such as GPT-3, GPT-Neo, PaLM, and more, to improve its performance.
The below highlights the main modifications compared to the original Transformer architecture published in 2017.
Note: in the below headings, [.] indicates where they found inspiration for the change.
1.1 Pre-normalization [GPT-3]
The original Transformer architecture applies layer normalization after the self-attention and feed-forward layers. LLaMA normalizes the input to the self-attention and feed-forward layers (pre-normalization). Pre-normalization is pretty standard among transformer-based LLMs nowadays.
They use the RMSNorm (Root Mean Square Layer Normalization), which is simpler and more efficient than layer normalization, yet achieves similar performance.
About RMSNorm
Suppose we have a feed-forward network that takes an input x ∈ ℝm, and outputs y ∈ ℝn.
where f is the activation function, wij and bi are the weights and biases, respectively.
This network may suffer from an internal covariate shift, which is the change in the distribution of network activations due to the change in network parameters during training. We can normalize the input to the activation function to solve this problem.
Layer normalization normalizes the input x to have zero mean and unit variance.
where gi is a learnable gain parameter (initially set to 1), and 𝜇 and 𝜎 are the mean and standard deviation of ai, respectively.
A well-known explanation for the success of layer normalization is the re-centering and re-scaling invariance property, which gives the input to the activation function the same mean and variance. However, the authors of RMSNorm hypothesize that the re-scaling invariance is the key to the success of layer normalization.
As such, they propose RMSNorm, which normalizes the input to have re-scaling invariance but does not re-center the input.
The authors of RMSNorm show that RMSNorm achieves similar performance to layer normalization while being simpler and more efficient.
1.2 SwiGLU Activation Function [PaLM]
The original Transformer architecture uses ReLU as the activation function in the feed-forward layer. In contrast, LLaMA uses SwiGLU, a variation of GLU (Gated Linear Unit), to improve the performance of the feed-forward layer.
SwiGLU is a variant of GLU, replacing the sigmoid activation function with Swish.
where W and V are learnable weight matrices, and ⊗︀ is the element-wise multiplication.
The Swish activation function is as follows:
where 𝜎 is the sigmoid function. They use PyTorch’s silu (Sigmoid Linear Unit, another name for Swish), which does not have the 𝞫. Therefore, 𝞫 = 1.
Note: I’ve written an article that explains more details on SwiGLU and other GLU variants.
1.3 Rotary Embeddings [GPTNeo, RoFormer]
The original Transformer architecture uses (absolute) positional embeddings to encode the position of each token in the sequence. LLaMA uses RoPE (rotary positional embeddings), first appearing in the RoFormer paper.
It encodes absolute position with a rotation matrix and incorporates relative position dependency in self-attention.
For example, a rotation matrix Rd𝚯,m defines a rotation in d-dimensional space by an angle 𝚯 for the m-th position.
Note: d is the dimension of the token embeddings, and it must be even.
In two-dimensional space, the rotation matrix for the first position R2𝚯,1 is as follows:
where 𝜽1 = 1000-2(1-1)/2 = 1. In other words, the above matrix rotates the first token by 𝜽1 degrees.
The rotation matrix for the second position R2𝚯,2 is as follows:
So, the above matrix rotates the second token by 2𝜽1 degrees.
Therefore, the position of the second token relative to the first token is 2𝜽1$ - 𝜽1 = 𝜽1 degrees.
In general, the attention score between the m-th and n-th positions is as follows:
- xm and xn are the token embeddings for the m-th and n-th positions.
- Wq and Wk are learnable weight matrices for the query and key.
- Rd𝚯, n-m = (Rd𝚯, m)T Rd𝚯, n since the transpose of a rotation matrix means the inverse rotation.
Below is Figure 1 from the RoPE paper showing how the rotation matrix encodes the relative position.

RoPE is a robust way to encode relative position dependency in self-attention, and the RoPE paper’s experiments show that it outperforms the original Transformer’s absolute positional embeddings.
1.4 Efficient Causal Multi-Head Attention [xformers]
The original Transformer architecture uses a causal multi-head attention layer, which masks the future tokens in the sequence. However, it is inefficient as it computes the attention scores for all tokens in the sequence before masking the future ones.
LLaMA uses a more efficient causal multi-head attention layer, which only computes the current and past token’s attention scores. Instead of using the autograd function from PyTorch, they implemented a more efficient backward function to reduce the memory footprint.
2 LLaMA Training Configuration
They trained large transformers on extensive textual data, with the restriction of only using data that is publicly available and compatible with open sourcing. Otherwise, they reuse data sources leveraged to train other LLMs.
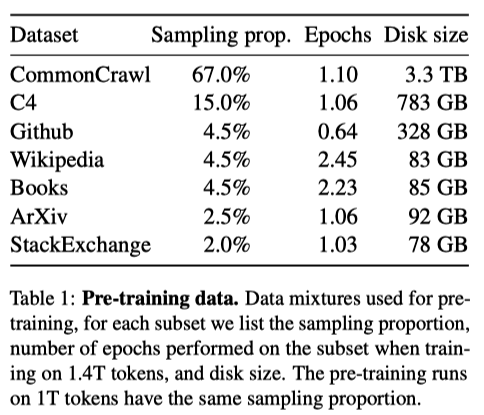
They used the AdamW optimizer with the following hyperparameters:
- 𝞫1 = 0.9, 𝞫2 = 0.95
- A cosine learning rate schedule with a warmup of 2000 steps (the final learning rate is 10% of the maximal learning rate)
- A weight decay of 0.1
- Gradient clipping at 1.0
- Various learning rates and batch sizes based on the model sizes
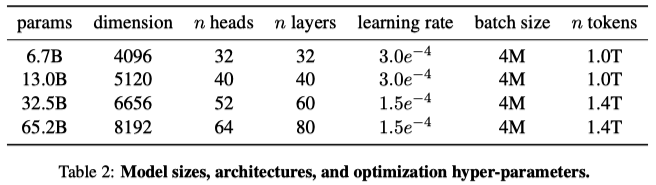
3 LLaMA Performance
Table 3 shows the zero-shot performance of LLaMA on various benchmarks.
- LLaMA-13B outperforms GPT-3 on most benchmarks despite being 10× smaller.
- LLaMA-33B outperforms Chinchilla-70B on all reported benchmarks but BoolQ.
- LLaMA-65B surpasses PaLM-540B everywhere but on BoolQ and WinoGrande.

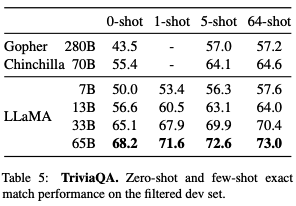
They also compared LLaMA with other LLMs on two closed-book question and answering tasks: TriviaQA and Natural Questions.
- LLaMA-13B is also competitive on these benchmarks with GPT-3 and Chinchilla, despite being 5-10× smaller. It runs on a single V100 GPU during inference.
- LLaMA-65B achieves state-of-the-art performance in the zero-shot and few-shot settings.

The paper has many more results, so I encourage you to read it if you are interested.
4 Conclusion
LLaMA is a family of LLMs trained on publicly available datasets and achieving state-of-the-art performance on various benchmarks. They are also more efficient than other LLMs.
More importantly, LLaMA got leaked, and people are now fine-tuning such powerful models on their machines in a matter of a few days. Such quick training is a game-changer for NLP research, enabling researchers to iterate faster and try out more ideas.
Moreover, there are versions of LLaMA whose inference can run on a smartphone. It would open up a realm of possibilities for intelligent assistants on our smart devices.
I look forward to seeing even more efficient LLMs being available to the public in the future.
5 References
- LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, Guillaume Lample - Self-attention Does Not Need O(n2) Memory
Markus N. Rabe, Charles Staats - Decoupled Weight Decay Regularization
Ilya Loshchilov, Frank Hutter - Root Mean Square Layer Normalization
Biao Zhang, Rico Sennrich - GLU Variants Improve Transformer
Noam Shazeer - RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu - Meta’s LLaMA Leaked to the Public, Thanks To 4chan
Analytics India Magazine - SwiGLU: GLU Variants Improve Transformer (2020)