Long Short-Term Memory
How LSTM Mitigated the Vanishing Gradients But Not the Exploding Gradients

In theory, RNNs (Recurrent Neural Networks) should extract features (hidden states) from long sequential data. Researchers had difficulty training the basic RNNs using BPTT (Back-Propagation Through Time).
The main reasons are the vanishing and exploding gradient problems, which LSTM (Long Short-Term Memory) mitigated enough to be more trainable but did not entirely solve the problem. Then, what are the remaining issues with LSTM?
To understand the issue, we need to know how BPTT works. Then, it will be clearer how the vanishing and exploding gradients occur. After that, we can appreciate why LSTM works better than the basic RNN, especially for long sequential data. Finally, we will understand why LSTM does not entirely solving the problems.
In this article, we discuss the following topics:
- BPTT (Back-Propagation Through Time)
- Vanishing and Exploding Gradients
- LSTM (Long Short-Term Memory)
- BPTT Through LSTM Cells
1 BPTT (Back-Propagation Through Time)
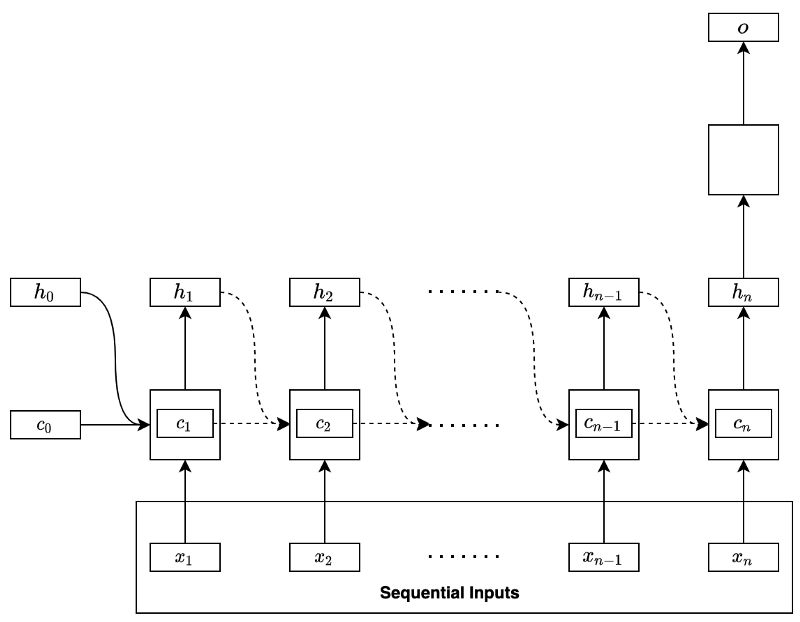
Let’s use a basic RNN to discuss how BPTT works. Suppose the RNN uses the final hidden state to predict (i.e., regression or classification) as shown below:
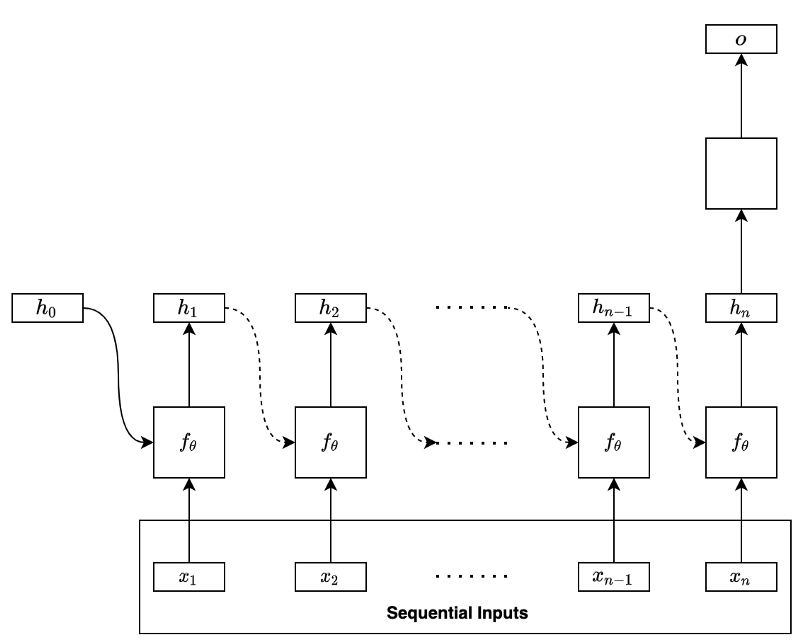
The model processes the input data sequentially:
In the first step, the RNN takes in the initial hidden state containing zeros and the input data’s first element to produce the hidden state of the first step. At the second step, the network takes in the first step’s hidden state and the input data’s second element to produce the hidden state of the second step. At each step, the network takes in the previous hidden state and the input data’s current element to produce the hidden state of that step.
We can mathematically summarize the process as follows:
Note: the parameters θ include all weights and biases from the network except for the layers that produce the final output.
We can unfold the final hidden state like below:
As we can see, the same function with the same parameters recurs to form a function
Therefore, the final hidden state contains features from the entire input sequence. The above model uses the final hidden state to perform regression or classification (in the empty square) to produce an output of the network.
When training the RNN, we calculate the error (loss) by comparing the model’s output and the label value from the training dataset. For example, we may use RMSE for regression and cross-entropy for classification. After that, we back-propagate the error through the network in reverse order.
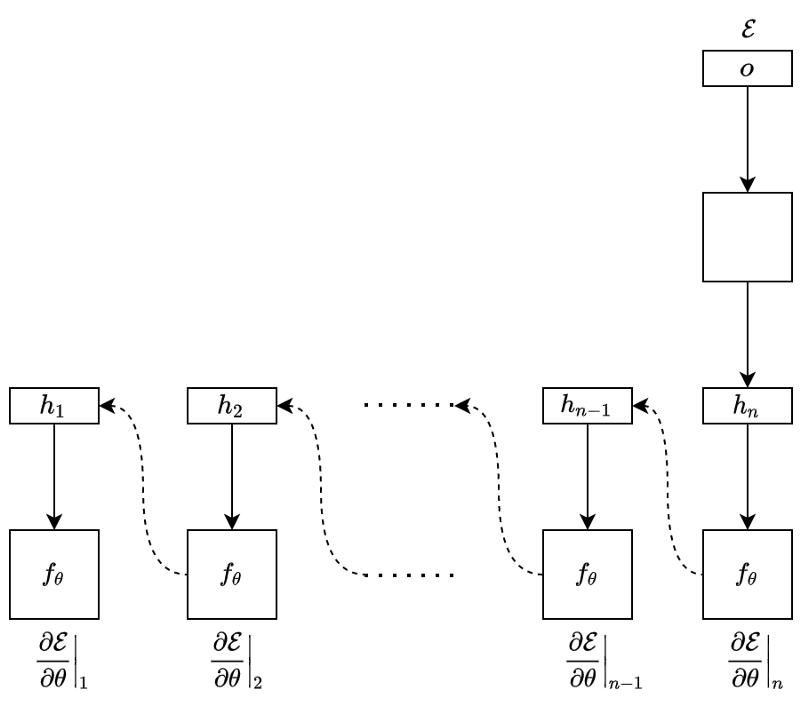
We call this operation BPTT (Back-Propagation Through Time). It is the same process as the back-propagation in plain neural networks, except that every backward step uses the same parameters to calculate the gradients.
At the step
At the step
In the step
And so forth.
We see the pattern clearly in the below diagram:
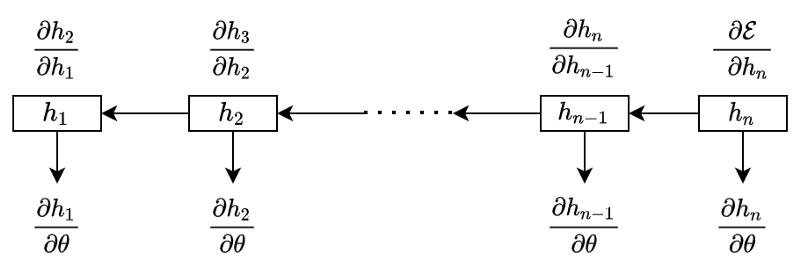
The total gradient is a sum of all the temporal contributions:
We can compactly express the above using the summation and product symbols:
Note: when
Also, when calculating a temporal contribution at
Now that we know how BPTT works, let’s look at how the vanishing and exploding gradients occur.
2 Vanishing and Exploding Gradients
If the sequential data is long (having many steps), there are a lot of multiplications of the partial derivatives while calculating the gradients.
For example, the gradient at the first step of a long sequential data is:
The intuition for vanishing gradients is as follows: if the magnitudes of multiplication by the partial derivatives are less than 1, the gradients will vanish when
The intuition for exploding gradients is as follows: if the magnitudes of multiplication by the partial derivatives are greater than 1, the gradients will explode when n is large:
To see how the above conditions happen, let’s look at the partial derivatives more closely by expanding the hidden state calculation (assuming the activation is
So, the gradient of a hidden state with respect to its immediate predecessor is:
The above equation may not be obvious. The following explains the calculation details (You can skip it if it’s not interesting).
We use the below substitution:
Now, the partial derivative is:
The second term becomes:
The first term is a bit more involved.
Let’s assume the vector
The hyperbolic tangent applies element-wise on the vector
Now we want to calculate the following:
This will be a Jacobian matrix in that we calculate all first-order partial derivatives of the vector-valued function
The first row contains all the first-order partial derivatives of the first element of
The diagonal elements are all ordinary derivatives, whereas non-diagonal elements all are zeros:
The dash in
Therefore,
Replacing the substitution z with the original definition:
In the above partial derivatives, we have the derivative of the hyperbolic tangent, the magnitude of which is less than one except when the input is zero. So, it could contribute to the vanishing gradient problem.
How about using a different activation like ReLU instead of
Unfortunately, the derivative of an activation function is just one side of the story. The whole partial derivative also depends on the weights
We now know that the problem depends on both the activation function and the weights applied to the hidden state. But we don’t know precisely under what conditions the vanishing or exploding gradients occur.
Let’s mathematically formalize the conditions for vanishing and exploding gradients. For any activation function
Note: for
Let’s also define the absolute value of the largest eigenvalue of the weight matrix
For the vanishing gradient problem, the sufficient condition is:
, because the norms of the matrices have the following inequality:
Note: the norm of matrix A gives the largest singular value of A. For a real-valued square matrix A, ||A|| returns the largest eigenvalue of matrix A. If the eigenvalues of matrix A are all less than 1, multiplying a vector by matrix A will make the output magnitude smaller than the original vector.
Similarly, for the exploding gradient problem, the necessary condition (not sufficient condition) is:
, because the bounding value of the partial derivatives becomes more than 1.
As we can see, the problem is fundamental to the recurrent architecture of RNNs. It would be very challenging to eliminate the vanishing and exploding gradient problems.
If so, what problem did LSTM mitigate, and how?
3 Long Short-Term Memory
LSTM introduced a new state called cell state that works as a long-lasting memory for useful features. To calculate the cell state, LSTM first calculates an intermediate cell state:
The superscript
The basic RNN would use the intermediate cell state as the hidden state. On the contrary, LSTM may not take everything from the intermediate cell state and calculates the cell state as below:
The circle dot means element-wise multiplication. We call
Therefore, the element values in the forget and input gates are between 0 and 1 inclusive. So, the forget gate determines how much to keep from the previous cell state, and the input gate determines how much to take from the intermediate cell state.
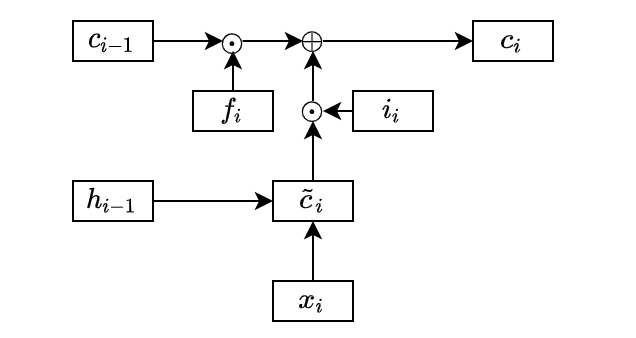
In the above diagram, I omitted the lines from the previous hidden state and the current input data into the forget and input gates for simplicity.
The usefulness of the forget gate is that it can reset some of the cell states. For example, the cell state may contain some details required for a while that it no longer needs. Without the forget gate, we have no way to erase unwanted information. As we are adding more information from the intermediate cell state to the cell state, it would be challenging to manage the information necessary in the cell state.
So, we know how LSTM updates the cell state. It can store long-lasting dependencies and also reset whatever and whenever required.
But what does it do with the cell state?
The cell state does not replace the hidden state — instead, it acts as a memory, storing dependencies that may or may not last long. As such, the cell state contains relevant information for the current hidden state as well, which LSTM extracts like below:
The output gate
In this way, the network may keep crucial information in the cell state for a long time while selecting immediately required information for the current hidden state.
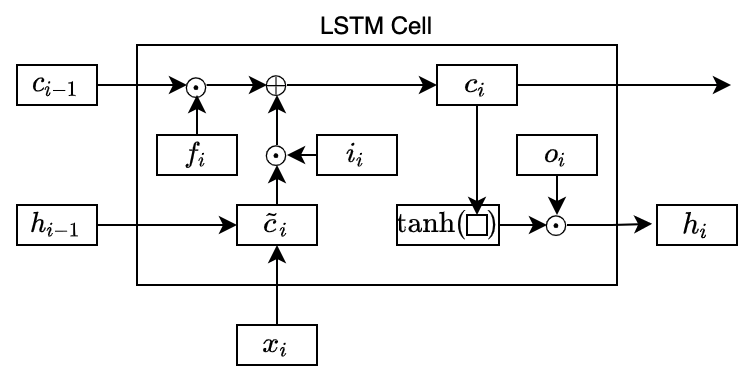
All the gates are neural networks with learnable parameters. So, LSTM learns what to forget/keep from the previous cell states and add from the intermediate cell state. The activated (
So, the complete formulas are:
We call the whole thing an LSTM cell (or block). We can replace the basic RNN hidden state calculation with an LSTM cell to form a complete recurrent neural network. Some RNN patterns are explained in the previous article, where we can drop the LSTM cell in.
Now that we understand how LSTM works, we want to examine BPTT to see how gradients flow through the cell states.
Will the vanishing and exploding gradient problems go away?
4 BPTT Through LSTM Cells
Let’s use the same architecture as previously discussed with the basic RNN. The network uses the last hidden state to predict an outcome, as shown below:

We calculate the gradient at each step:
And so forth. We add all the temporal contributions to have the whole gradient:
So, the following Jacobian matrix determines if the gradient vanishes or explodes:
Let’s look at the first term while ignoring the second term now. If the above Jacobian matrix depends only on the first term, how would it affect the vanishing and exploding gradient problems?
The elements of the forget gate are between 0 and 1 inclusive. So, we may still have the vanishing gradient problem. However, it occurs slower than the basic RNN because it does not involve the recurrent weight matrix, which, in the case of the basic RNN, rapidly drives the derivative to zero for long sequential data.
Moreover, the elements of the forget gate should have some values of approximately 1 to keep information forward. Overall, the gradients should be more resistant to vanishing gradients than the basic RNN.
The first term alone should not trigger the exploding gradients as the forget gate values are no more than 1.
However, the whole gradient could still explode because of the addition of the second term.
In practice, we may forcibly clip the norm of gradients to mitigate exploding gradient problems, even though it adds one more hyper-parameter (the max norm) that we need to calibrate.
For example, PyTorch has torch.nn.utils.clip_grad_norm_.
5 References
- Recurrent Neural Networks
- Learning Long-Term Dependencies with Gradient Descent is Difficult
Yoshua Bengio, Patrice Simard, Paolo Frasconi - On the difficulty of training recurrent neural networks
Razvan Pascanu, Tomas Mikolov, Yoshua Bengio - Learning Sequence Representations
Justin Bayer - Matrix Norm
Wikipedia