Longformer: The Long-Document Transformer (2020)
How it processes thousands of tokens

In 2020, researchers at Allen Institute for Artificial Intelligence (AI2) published Longformer: The Long-Document Transformer.
AI2 is a non-profit research organization that hosts the Semantic Scholar website providing AI-driven search and discovery tools for research publications. They crafted a new attention mechanism for processing long-document to overcome the issue with the original transformer architecture when scaling to long-form texts.
Longformer is an important work that influenced later works that must process long sequences like steams of video frames. This article explains the Longformer’s attention mechanism.
1 Problem with Long Sequence
The transformer is well-known for its self-attention mechanism in which each token in the input sequence refers to every token in the same sequence via dot-product operations. As such, the computation complexity in memory and space becomes
So, the computational complexity quadratically increases with the sequence length, which makes it very expensive to process long sequences. We could divide a long sequence into smaller chunks, but then we would lose the global context with the sequence, reducing the quality of the language task.
On the contrary, Longformer scales linearly with sequence length and can process thousands of tokens, thanks to its attention patterns.
2 Longformer Attention Patterns
Instead of full global attention, Longfomer uses a combination of different attention patterns.
- Sliding Window Attention
- Dilated Sliding Window
- Global + Sliding Window
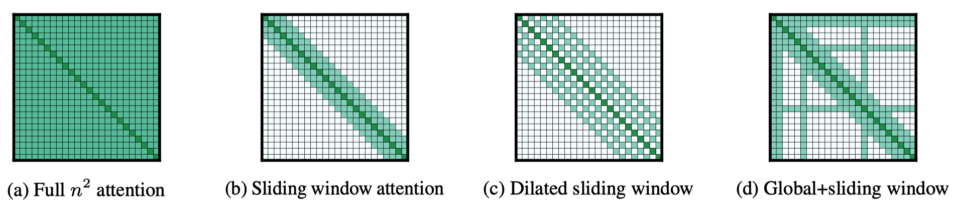
2.1 Sliding Window Attention
Longformer uses sliding window attention to build local context, applying the attention mechanism on neighboring tokens. Let’s imagine we have a sequence of ten tokens and discuss what sliding window attention does.

Suppose each token attends to 2 tokens on each side. The first token attends to the following tokens:
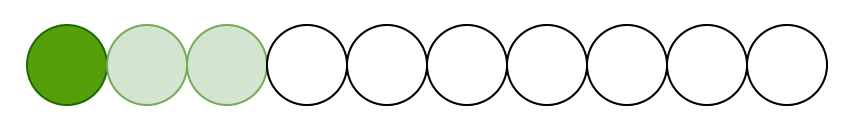
The second token attends to the following tokens:
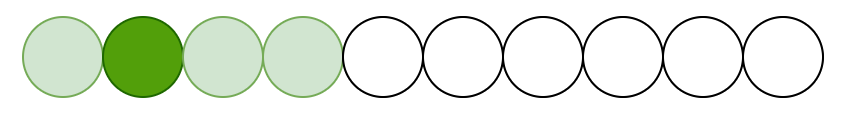
The third token attends to the following tokens:

The fourth token attends to the following tokens:

Continuing to the tenth token, we have the following sliding window attention pattern.

Multiple stacked layers of sliding window attention results in a large receptive field. The idea is similar to convolutional neural networks (CNNs) where top layers have access to all input locations, building global semantic representations. Through
The computational complexity is
2.2 Dilated Sliding Window Attention
Dilated sliding window increases the receptive field without increasing computation. It is analogous to dilated CNNs in that the sliding window has gaps of size dilation
The receptive field size of the topmost layer is
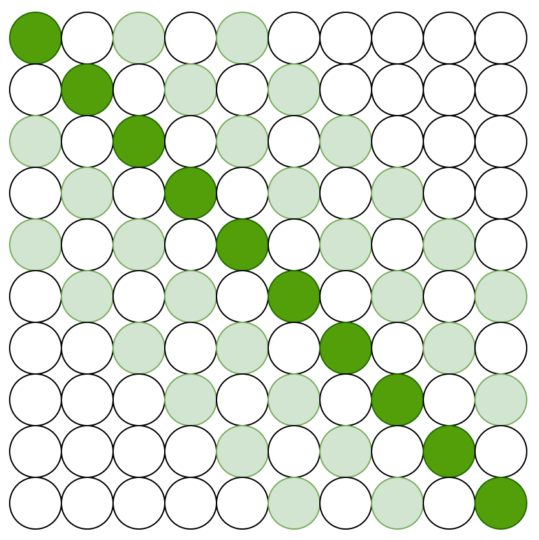
2.3 Global plus Sliding Window Attention
Longformer uses local attention to build contextual representations, but that is not enough to perform task-specific prediction, which requires full sequence representations. As such, they add global attention to a few pre-selected input locations.
In the below example, the first and seventh tokens are pre-selected. Those selected tokens attend to all tokens across the sequence. Also, all tokens (pre-selected or not) attend to the pre-selected tokens, making the global attention symmetric.
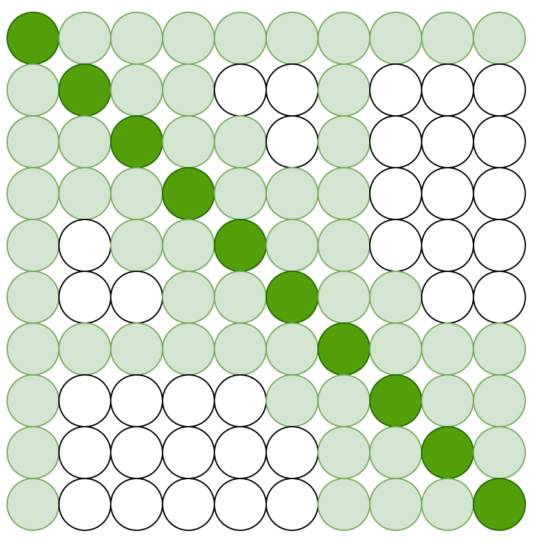
Which token should be pre-selected for global attention depends on the language task. For example, a classification task aggregates the representation of the entire sequence into a special token (i.e., CLS in the case of BERT). So, we should pre-select the special token for global attention.
In the case of QA (question-answering), all question tokens use global attention since the number of question tokens is relatively small, and the computational complexity of the combined local and global attention is still
2.4 Linear Projection for Local and Global attention
Given the linear projections Q, K, and V, the original transformer computes attention scores as follows:
Longformer uses two sets of projections: one for sliding window attention and the other for global attention:
Therefore, Longformer has the flexibility to use different types of attention, which improves performance on downstream tasks.
2.5 Sliding Window Size Consideration
Longformer uses small window sizes for the lower layers and increases window sizes towards higher layers. So, the lower layers collect local information, while higher layers learn higher-level representations of the entire sequence.
Also, Longformer does not use dilated sliding windows for lower layers to learn the local context well. For higher layers, it uses a small amount of increasing dilation only on two attention heads to attend to distant tokens, increasing the receptive fields.
3 Experiment results
3.1 Latency and Memory Usage
The below shows the runtime and memory of full self-attention and different implementations of Longformer’s self-attention.

- Longformer-loop is a PyTorch implementation (non-vectorized) and supports dilation (but slow)
- Longformer-chunk is vectorized but does not support dilation (used for pretraining/finetuning)
- Longformer-cuda uses an optimized custom cuda kernel using TVM
The memory usage of Longformer scales linearly with the sequence length, while the full self-attention mechanism runs out of memory for long sequences.
3.2 Performance Comparison
Longformer outperforms RoBERTa on long document tasks using datasets like WikiHop.

Longformer sets new state-of-the-art results on WikiHop and TriviaQA.

3.3 Longformer-Encoder-Decoder (LED)
Longformer-Encoder-Decoder (LED) is a variant of Longformer for generative sequence-to-sequence tasks. The encoder uses the efficient local+global attention pattern of the Longformer, while the decoder uses the full self-attention to the entire encoded tokens and previously decoded locations.
The below shows its effectiveness on the arXiv summarization dataset.

- R-1 (ROUGE-1) metric uses the overlap of unigram with reference summaries.
- R-2 (ROUGE-2) metric uses the overlap of bigram with reference summaries.
- R-L (ROUGE-L) metric uses the overlap of n-gram with reference summaries.
4 References
- RoBERTa — Robustly optimized BERT approach
- Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, Arman Cohan