Temporal Convolutional Networks
Can CNNs handle sequential data and maintain history better than LSTM?
This article reviews a paper titled An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling by Shaojie Bai, J. Zico Kolter, and Vladlen Koltun.
Before TCNs, we often associated RNNs like LSTMs and GRUs with a new sequence modeling task. However, the paper shows that TCNs (Temporal Convolutional Networks) can efficiently handle sequence modeling tasks and outperform other models. The authors also demonstrated that TCNs maintain more extended memory than LSTMs.
We discuss the architecture of TCNs with the following topics:
- Sequence Modeling
- Causal Convolutions
- Dilated Convolutions
- Residual Connections
- Advantages and Disadvantages
- Performance Comparisons
1 Sequence Modeling
Although the paper is not the first to use the term TCN, it means a family of architectures that uses convolutions to process sequential data.
So, let’s define sequence modeling tasks.
Given an input sequence:
, we wish to predict corresponding outputs at each time:
So, a sequence modeling network in the paper is a function
There is a constraint (the causal constraint): when predicting an output for time
And we must not use inputs from the later time points than
The objective of the above sequence modeling setting is to find a network
This setup is more restricted than general sequence-to-sequence models, such as machine translation which can use the whole sequence to perform predictions.
So, the TCN is causal (no information leakage from the future to the past) and can map any sequence to an output sequence of the same length.
Moreover, it can use a very-deep network with the help of residual connections, and it can look very far into the past to predict with the help of dilated convolutions.
The following will discuss the characteristics mentioned above (casual, dilated, and residual).
2 Causal Convolutions
The TCN uses 1D FCN (1-dimensional fully-convolutional network) architecture.
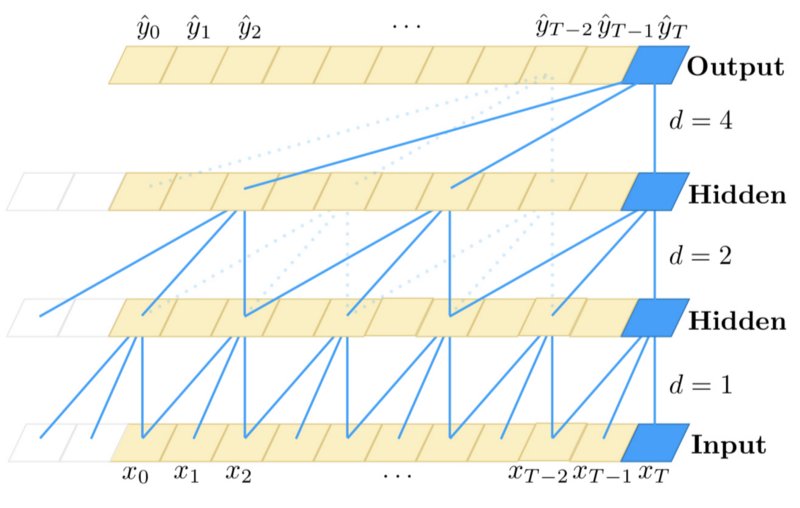
Each hidden layer has the same length as the input layer, with zero paddings to ensure the subsequent layer has the same length.
For an output at time
The causal convolution is not new, but the paper incorporates very-deep networks to allow a long history.
3 Dilated Convolutions
If we look back at consecutive time steps, we can only look back up to the number of layers in the network.
To overcome the problem, they adapted dilated convolutions which take inputs from every
where
The idea of the causal convolution and the dilated convolution originated from the WaveNet paper, which has a very similar architecture as the TCN.
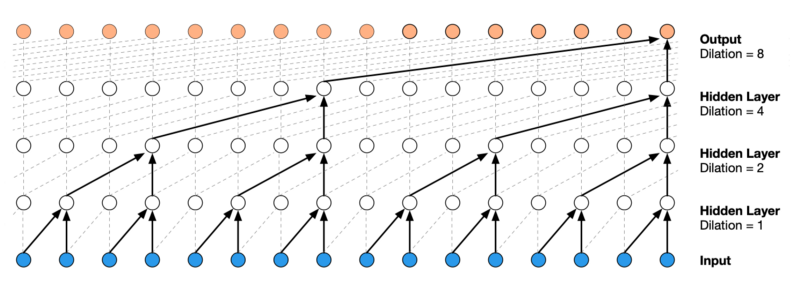
Dilated convolution lets the network look back up to
The authors of the TCN paper increased
where
Below is the same diagram for convenience. The dilated convolution on the first hidden layer applies every two steps where
The arrangement of the dilated convolutions ensures that some filter hits each input within the history and allows a long history using deep networks.
You can follow the blue lines from the top to the bottom layers to see if they reach all the inputs at the bottom, meaning the prediction at time
4 Residual Connections
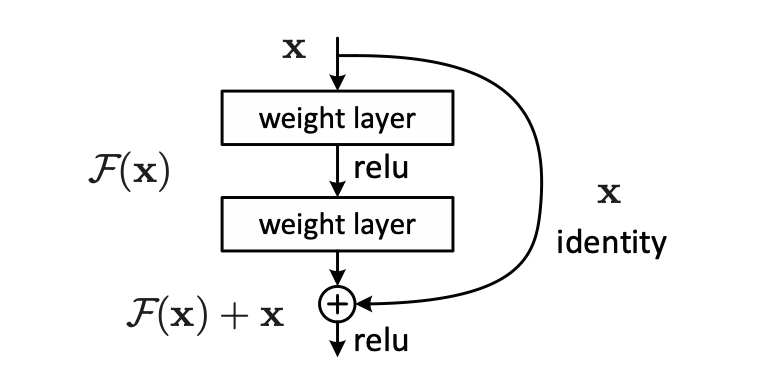
A residual block (originally from ResNet) allows each layer to learn modifications to identity mapping and works well with very-deep networks.
The residual connection is essential to enable a long history. For example, if a prediction depends on a history length of 2 to the power of 12, we need 12 layers to handle such a large receptive field.
Below is the residual block of the baseline TCN.
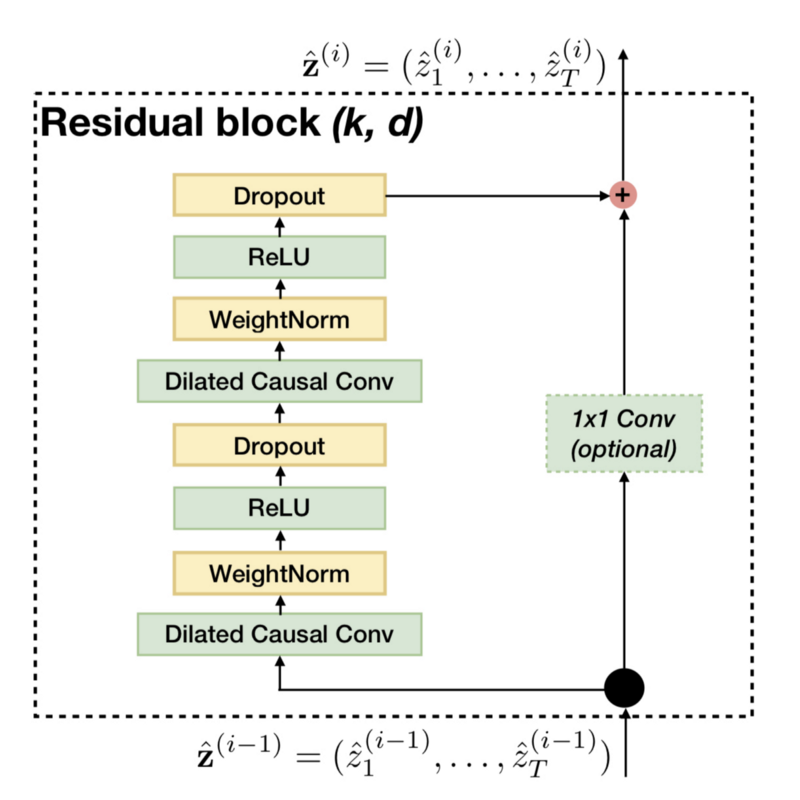
The residual block has two layers of dilated causal convolution, weight normalization, ReLU activation, and dropout.
There is an optional 1x1 convolution if the number of input channels differs from the number of output channels from the dilated causal convolution (the number of filters of the second dilated convolution).
It is for ensuring the residual connection (element-wise addition of the convolution output and input) works.
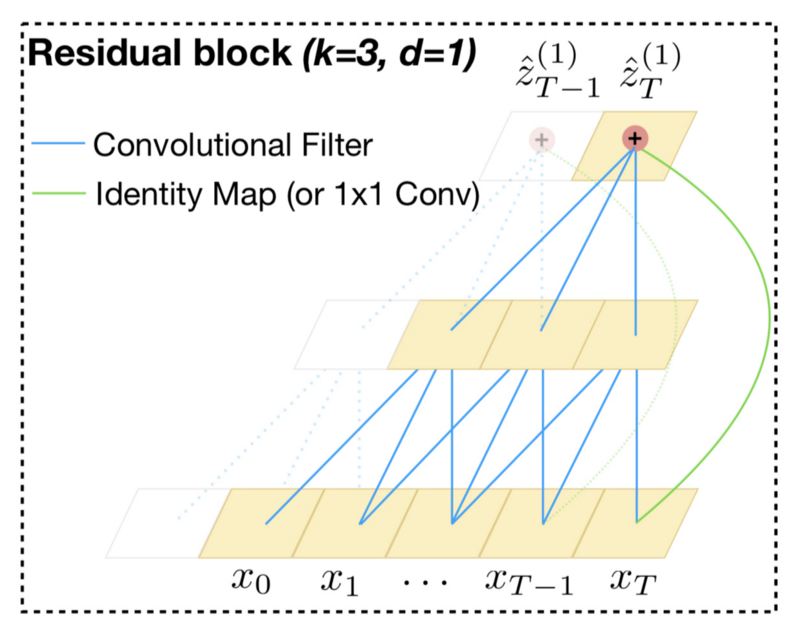
5 Advantages and Disadvantages
In summary,
TCN = 1D FCN + Dilated Causal Convolutions
, which is a straightforward structure and easier to understand than other sequence models like LSTM.
Apart from the simplicity, there are the following advantages of using TCNs over RNNs (LSTMs and GRUs):
- Unlike RNNs, TCNs can take advantage of parallelism as they can perform convolutions in parallel.
- We can adjust the receptive field sizes by the number of layers, dilation factors, and filter sizes, which allows us to control the model’s memory size for different domain requirements.
- Unlike RNNs, the gradients are not in the temporal direction but in the direction of the network depth, which makes a big difference, especially when the input length is very long. As such, the gradients in TCNs are more stable (also thanks to the residual connections).
- The memory requirement is lower than LSTMs and GRUs because each layer has only one kernel. In other words, the total number of kernels depends on the number of layers (not the input length).
There are two notable disadvantages:
- During an evaluation, TCNs take the raw sequence up to the required history length, whereas RNNs can discard a fixed-length chunk (a part of the input) as it consumes them and keep only the summary as a hidden state. Therefore, TCNs may require more data storage than RNNs during evaluation.
- Domain transfer may not work well with TCNs, especially when moving from a domain requiring a short history to another domain needing a long history.
6 Performance Comparisons
The authors compared the performance of LSTM, GRU, RNN, and TCN using various sequence modeling tasks:
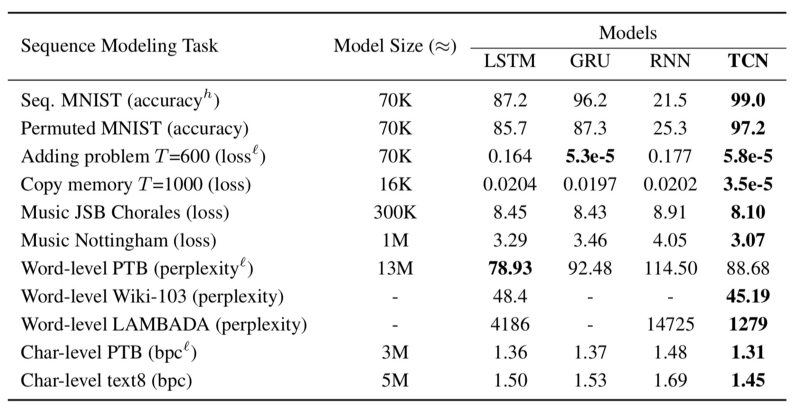
As you can see, TCN performs better than other models in most tasks.
One interesting experiment is the copy memory task, which examines a model’s ability to retain information for different lengths of time.
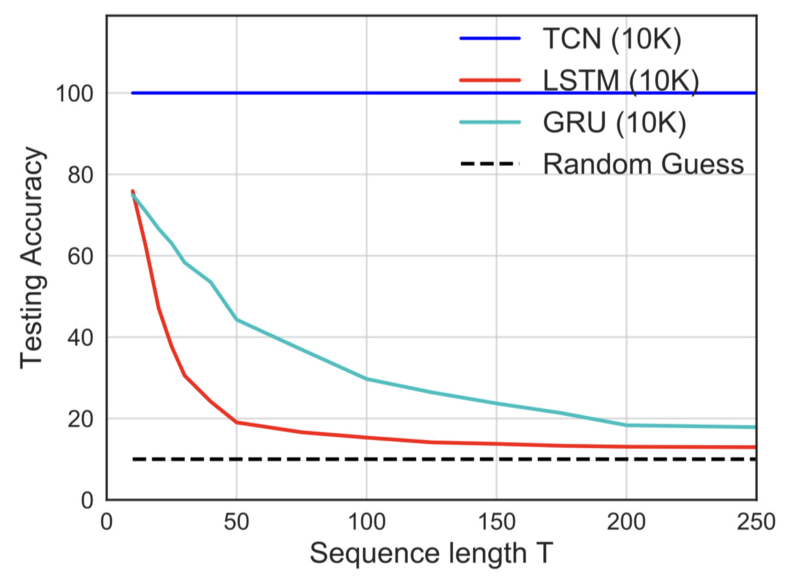
TCN achieved 100% accuracy on the copy memory task, whereas LSTM and GRU degenerate to random guessing as the time length T grows. It may be obvious considering the network structure of TCN, which has a straightforward convolutional architecture.
Overall, TCNs perform very well over LSTMs. The confidence of the authors shows in the following quote from the paper:
The preeminence enjoyed by recurrent networks in sequence modeling may be largely a vestige of history. Until recently, before the introduction of architectural elements such as dilated convolutions and residual connections, convolutional architectures were indeed weaker. Our results indicate that with these elements, a simple convolutional architecture is more effective across diverse sequence modeling tasks than recurrent architectures such as LSTMs. Due to the comparable clarity and simplicity of TCNs, we conclude that convolutional networks should be regarded as a natural starting point and a powerful toolkit for sequence modeling. Source: the paper
They provided the source code in their GitHub repo so you can try and see it for yourself.
7 References
- Long Short Term Memory
- An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Shaojie Bai, J. Zico Kolter, Vladlen Koltun
GitHub - WaveNet: A Generative Model for Raw Audio
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu - Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun