Transformer’s Self-Attention
Why Is Attention All You Need?

In 2017, Vaswani et al. published a paper titled Attention Is All You Need for the NeurIPS conference. The transformer architecture does not use recurrence or convolution. It solely relies on attention mechanisms.
In this article, we discuss the attention mechanisms in the transformer:
- Dot-Product And Word Embedding
- Scaled Dot-Product Attention
- Multi-Head Attention
- Self-Attention
1 Dot-Product And Word Embedding
The dot-product takes two equal-length vectors and returns a single number.
We use the dot operator to express the dot-product operation. We also call it the inner product as we calculate element-wise multiplication (that is, “inner product”) and sum those products together.
The geometric definition of the dot product is as follows:
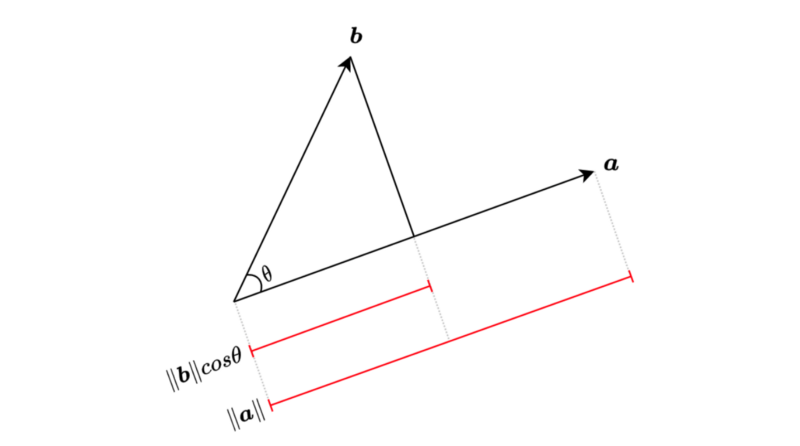
We can also project vector
The dot-product
Before discussing dot-product attention, we should talk about word embeddings as it gives us some intuition on how dot-product attention works.
Word embeddings use distributed representations of words (tokens), which is more efficient than one-hot vector representation. The word2vec and GloVe (Global Vectors for Word Representation) are well-known pre-trained word embeddings. Those word embedding vectors allow us to decompose a word into analogies.
The following diagram shows how we can decompose king and queen using word embedding vectors.
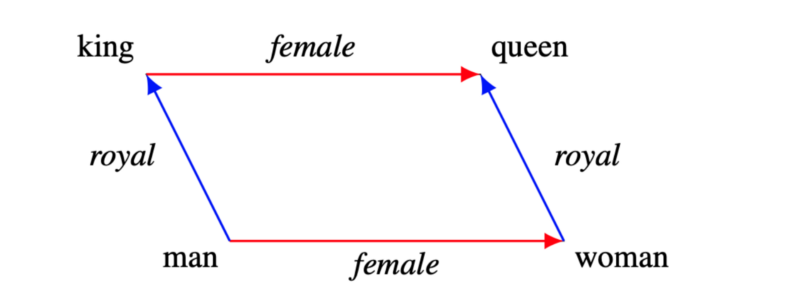
In other words, a word vector may contain multiple semantics. Hypothetically, we could query if a word vector has “royal” by projecting the vector with some matrix operation.
The question is: can a language model automatically learn to query different meanings and functions of each word in a sentence?
The transformer learns word embeddings from scratch, learns matrix weights for word vector projections, and calculates the dot-products for attention mechanisms. In the next section, we discuss how those vector mathematics work together.
2 Scaled Dot-Product Attention
Say we have a model that translates an English sentence
For simplicity, we express a word vector as a row vector with four dimensions.

We use a 4x3 matrix
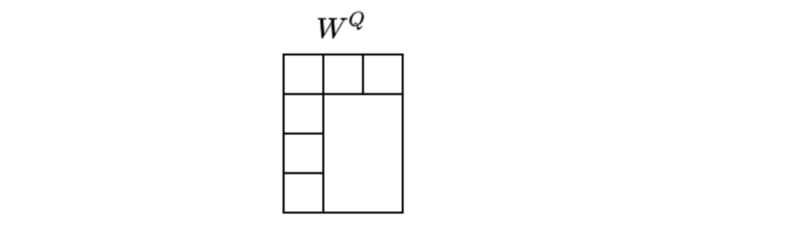
It’s a simple matrix multiplication on the word vector
As you can see, the dimension of
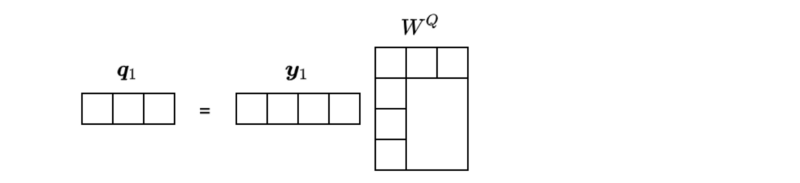
In this example, the dimension of the resulting vector became three.
We also project word vectors in
Again, the dimension of
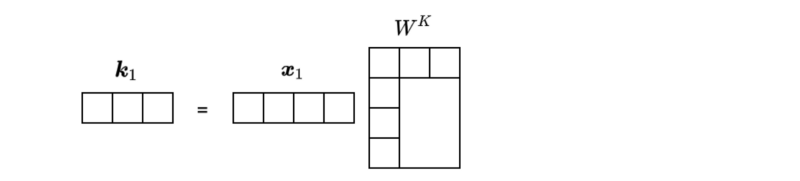
However, the dimension of
We apply the dot-product to see how strong these projected features (we call them query
We can calculate the dot-product by transposing vector

The result is a scalar value. Let’s call it “score”. As noted above, we also call vector
Since we are using a linear transformation, we can calculate scores between multiple word-vectors by a simple matrix operation.
Sentence
We can apply the following matrix operation to extract keys from sentence
We can apply the dot-product between the query
We now have a list of scores that tells us how the query
The weights indicate how much the model should pay attention to each word in sentence
We use the attention weights to extract a context from sentence
The dimension of vectors in
We calculate the weighted sum of value vectors using the attention weights:
The weighted sum of value vectors represents a context from sentence
We can extend the logic to multiple words
We represent all queries in a matrix:
So, we can calculate the attention vectors for all tokens in sentence
The scaling
The paper explains the reason, assuming a scenario where the elements of the query and key vectors are independent random variables with mean 0 and variance 1. The dot-product of vectors
In short, more dimensions tend to produce larger scores, which is problematic because the softmax function uses the exponential function, pushing large values even larger.
The following example Python script should clarify the reason:
import numpy as np
def softmax(x):
return np.exp(x)/np.exp(x).sum()
s1 = np.array([1.0, 2.0, 3.0, 4.0])
s2 = s1 * 10
print(f’s1: {softmax(s1)}’)
print(f’s2: {softmax(s2)}’)The output is as follows:
s1: [0.0320586 0.08714432 0.23688282 0.64391426]
s2: [9.35719813e-14 2.06106005e-09 4.53978686e-05 9.99954600e-01]The weights in s2 except the last element are almost zero, which makes the gradients very small.
Let me explain the reason why the gradients become small.
Suppose the softmax probability of class
Then, the partial derivatives of the softmax with respect to the variable
So, it’s like
As such, Vaswani et al. introduced the scaling factor, and they call the attention mechanism “scaled dot-product attention”.
3 Multi-Head Attention
A word could have a different meaning or function depending on the context. So, we should use multiple queries per word rather than just one.
In the paper, they use eight parallel attention calculations. They call each attention function “head”. In other words, they used eight heads (h=8).
The base transformer uses 512-dimensional word vectors projected into eight vectors of 64 (=512/8) dimensions — yielding eight representation subspaces. The scaled product-dot attention processes each of the eight representations using a different set of projection matrices:
Even though we have eight sets of matrix operations, we can perform them in parallel. So, it’s very fast.
The next step of the multi-head attention is to concatenate all eight heads and apply one more matrix operation
Note: I’m using a slightly different notation than the paper to keep similar usage of Q, K, and V from the scaled dot-product attention section.
Since we use the same number of dimensions (=64) for value vectors, the concatenated vectors restore the original dimension (=64x8=512). But they could also use a different number of dimensions for value vectors because _W_O can adjust the final vector dimension.
The transformer uses multi-head attention in multiple ways. One is for encoder-decoder (source-target) attention where Y and X are different language sentences. Another use of multi-head attention is for self-attention, where Y and X are the same sentences.
4 Self-Attention
A word can have a different meaning or function depending on the word itself and the words around it.
For example, in the below two sentences, the word “second” has different meanings:
Give me a second, please.
I came second in the exam.
But there is only one-word embedding for the word “second”. However, the meaning of “second” depends on its context. So, we must treat the word “second” with its context.
Let’s look at another example.
My dog chases after the thief.
The above sentence shows a functional relationship between “dog” and “chases”. We also see another relationship between “after” and “thief”.
In summary, we need to extract word contexts and relationships within a sentence, where self-attention comes into play.
With self-attention, all queries, keys, and values originate from the same sentence. So, we use multi-head attention like MultiHead(X, X) to extract contexts for each word in a sentence.
Self-attention handles long-range dependencies well compared with RNN and CNN. For RNN, we have diminishing gradients that even LSTMs can not eliminate. CNN can only associate data within the kernel size. Self-attention has none of those issues. Moreover, self-attention operations can run parallel and much faster than sequential processing like RNN cells.
Also, we can visually inspect self-attention, making it more interpretable. The paper has a few visualizations of the attention mechanism. For example, the following is a self-attention visualization for the word “making” in layer 5 of the encoder.
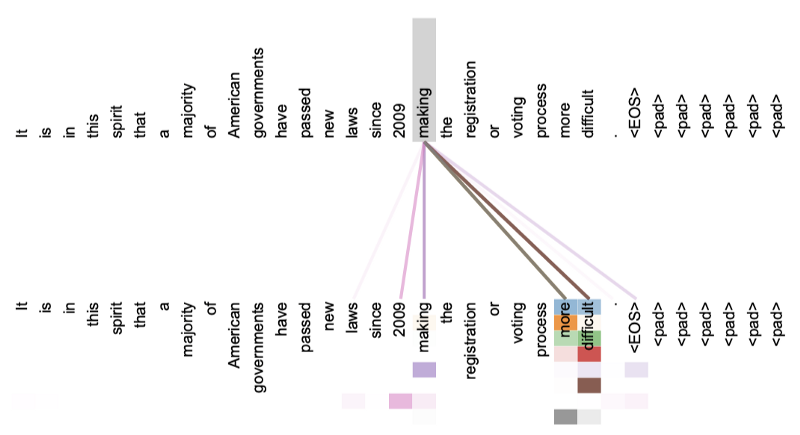
There are eight different colors with various intensities, representing the eight attention heads.
It is clear there is a strong relationship between “making” and “more difficult”.
The below image shows the word “its” and the referred words in layer 5 of the encoder (isolating only attention head 5 and attention head 6).
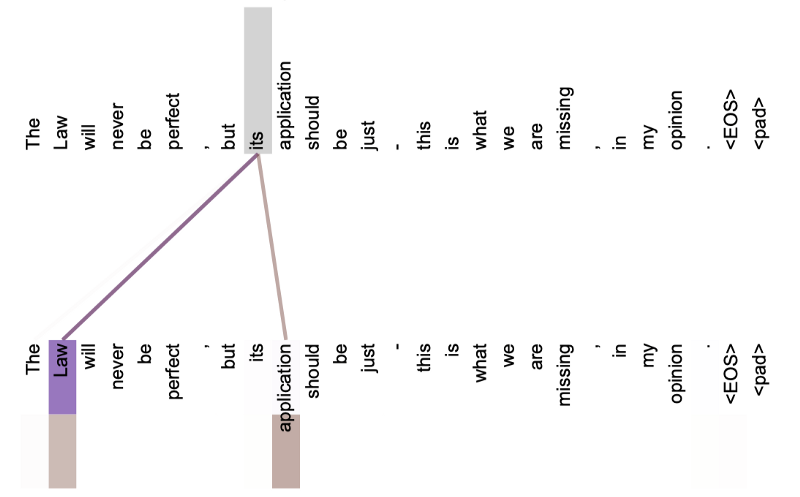
The word “its” has strong attention to “Law” and “application”.
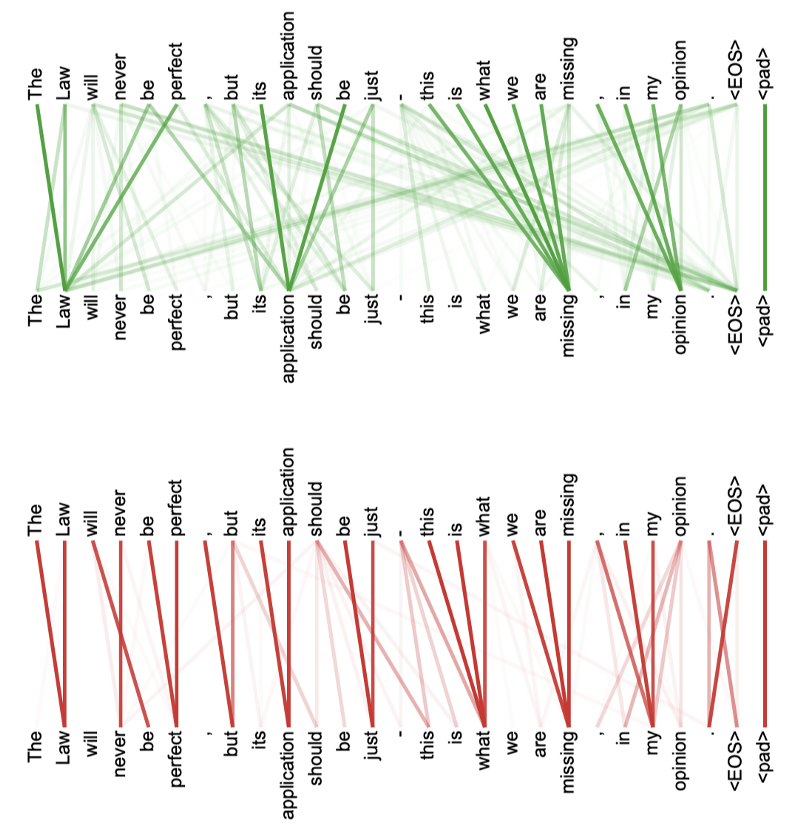
The below shows two heads separately (green and red). Each head seems to have learned to perform different tasks based on the structure of the sentence.
5 References
- Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin - The Annotated Transformer
Harvard NLP - The Illustrated Transformer
Jay Alammar