ViT: Vision Transformer (2020)
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

In 2020, the Google Brain team developed Vision Transformer (ViT), an image classification model without a CNN (convolutional neural network). ViT directly applies a Transformer Encoder to sequences of image patches for classification. So, ViT eliminated CNN from image classification tasks.
This article explains how ViT works.
1 Vision Transformer Architecture
1.1 Vision Transformer Overview
The idea is simple: ViT splits an image into a sequence of image patch embeddings mixed with positional encoding and feeds them into a Transformer Encoder. ViT has a classification head (MLP - multi-layer perception), which produces the final prediction. The below figure shows an overview of Vision Transformer architecture.
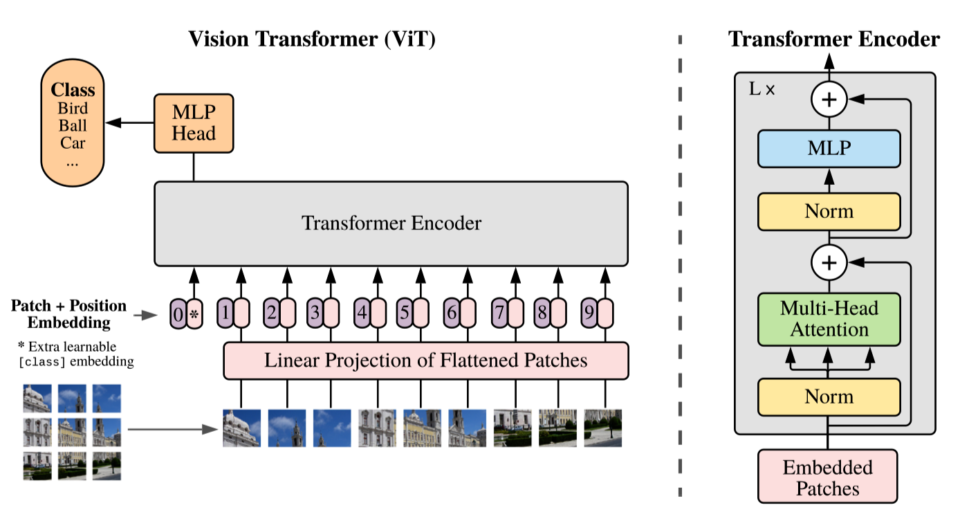
More concretely, ViT reshapes an image of shape H x W x C (height, width, channel) into a sequence of flattened patches: N x (P^2 C), where P is the patch size, and N is the number of patches:
According to the paper, ViT does the following:
- ViT uses a trainable linear project to map flattened patches from P^2 C to P^2 D, where D is an embedding vector size that the Transformer Encoder uses throughout its layers. They call them “patch embeddings”“.
- ViT prepends a learnable embedding (similar to BERT’s [CLS]), and the final hidden state of that is the aggregate representation of image patches used for classification tasks.
- ViT adds 1D position embeddings (learned) to the patch embedding to retain positional information. They didn’t use more advanced 2D position embeddings as they did not observe better performance gains.
In the official implementation (below), they use a convolution layer with kernel size = patch size (say, 16 for 16 x 16), strides to the same size (= 16), and the output channels (features) to the hidden size (D). In other words, the convolution layer creates a grid of embeddings that is flattened later.
# We can merge s2d+emb into a single conv; it's the same.
x = nn.Conv(
features=self.hidden_size,
kernel_size=self.patches.size,
strides=self.patches.size,
padding='VALID',
name='embedding')(x)1.2 Transformer Encoder as a Feature Extractor
So, the encoder plays the role of a feature extractor instead of a CNN backbone. However, it has much less image-specific inductive bias than CNNs. Convolutional kernels have built-in structures to handle two-dimensional neighborhood relationships and ensure translation equivariance. In ViT, self-attention layers are global. They even use 1D position embeddings, not 2D. The only time ViT considers 2D structure is at the beginning while cutting the image into patches.
I find it very interesting that ViT does not rely on 2D much. Also, as we’ll see in the next section, ViT performs better when pre-trained on larger datasets. Therefore, a global attention mechanism and pre-training with massive datasets can perform better than human-engineered structures like a convolutional kernel and max-pooling. Similarly, humans can guess the original image from image patches thanks to the flexible brain system (which we don’t fully understand) and prior experiences observing many objects.
2 Vision Transformer Experiments
2.1 Performance Comparison with Baseline Models
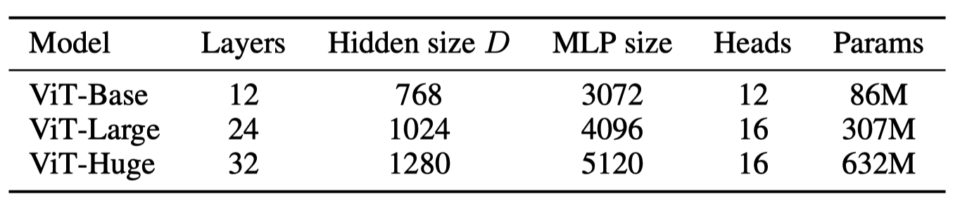
ViT has the following variants:
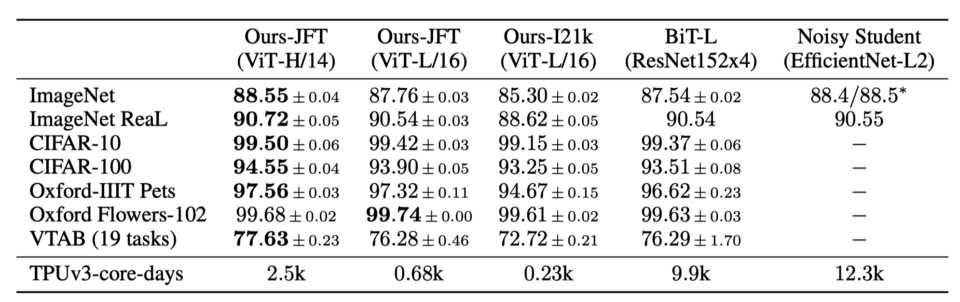
In the below table, ViT-Huge performs better than BiT-L ResNet152x4 and Noisy Student EffcientNet-L2 on most of the datasets. ViT-Large and ViT-Huge also perform comparably with those two baseline models.
Note: ViT-L/16 means the “Large” variant with a 16 × 16 input patch size.
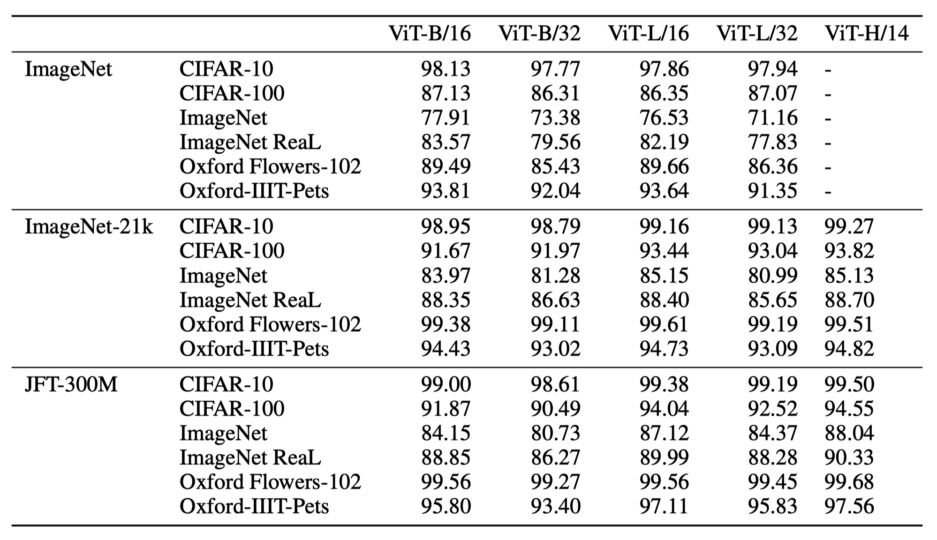
2.2 The Effect of Pre-training on Large Datasets
They pre-trained ViT models on ImageNet, ImageNet-21K, or Google’s proprietary JFT-300M datasets and then fine-tuned for downstream datasets to measure performance. They found that ViT performs better when pre-trained on larger datasets. It’s similar to how BERT performs better when pre-trained on larger datasets.
2.3 Attention Visualization
Below are examples of attention from the output token to the input space. We can see that ViT can capture the main object in images (especially for the first two examples).

2.4 Self-Supervised Masked Patch Prediction
They experimented with ViT on masked patch prediction, similar to how BERT used masked language modeling tasks for self-supervised training. The smaller ViT-B/16 model achieved 79.9% accuracy on ImageNet, a 2% improvement compared with training from scratch. However, it is 4% behind supervised pre-training. It is an area for further research.Finally, the author mentions that further scaling (to billions of parameters) of ViT would likely lead to improved performance, which we can see in the Scaling Vision Transformers paper in 2021.
3 References
- Transformer’s Encoder-Decoder
- BERT — Bidirectional Encoder Representation from Transformers
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby - Big Transfer (BiT): General Visual Representation Learning
Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, Neil Houlsby - Self-training with Noisy Student improves ImageNet classification
Qizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le - Scaling Vision Transformers
Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, Lucas Beyer